
1. 정보 검색
- 우리가 미리 수집해둔 collection에서 사용자의 needs의 결과를 자동으로 찾아주는 것
- 관련 자료 ; https://www.cs.virginia.edu/~hw5x/Course/IR2015/_site/lectures/
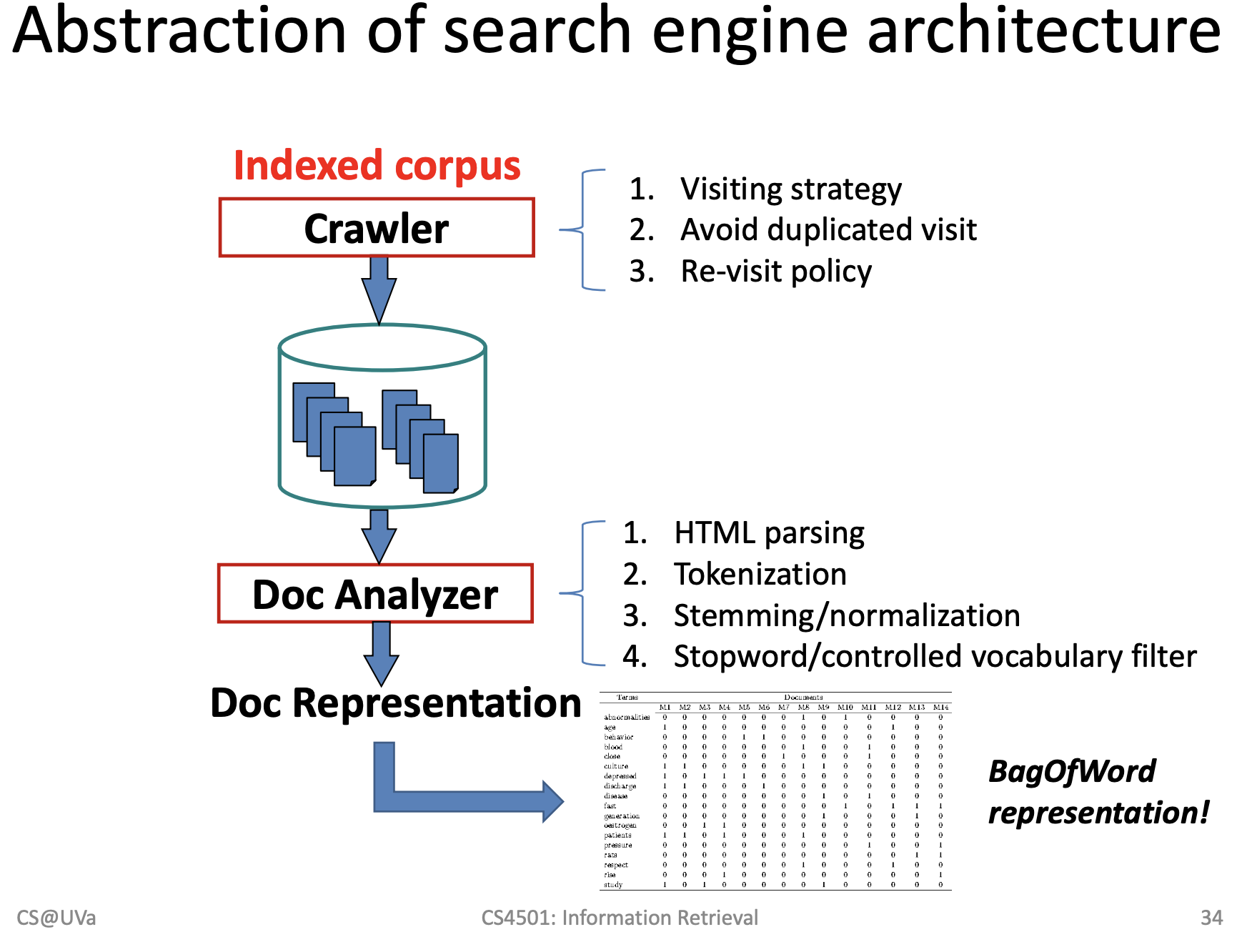
1) 순서
Crawler => Repository -> Doc Analyzer => Doc Representation -> Indexer => Index
사용자의 입력 -> 랭킹 계산 -> 적응형으로 피드백을 받아서 모델을 수정
2. Core IR
1) Document
- 사진, 문서, 문자 등의 데이터
2) Relevant
- 연관성
3) Web crawler
- 데이터 수집
4).Document analyzer & indexer
- 데이터를 정제하고 인덱싱 하는 것
3. 브라우징 vs Querying
1) browsing
- 사용자 본인이 뭘 찾고 싶은지 모를 때 사용하는 방식
2) querying
- 사용자 본인이 정확히 무엇을 원하는 지 알고 있을 때 사용하는 방식
3) 포털 사이트
- 두가지를 하이브리드 형태로 뉴스도 보여주고 검색도 해주는 형태
4. Pull vs Push
1) Pull
2) Push
5. Focused crawling
- 특정 타겟을 대상으로 만듦
- 어떤 사이트를 어떤 순서로 할 것인지 확인
Bag -of-Words 모델
- 모든 단어를 뽑고 각 단어가 독립적이다라는 가정을 한 후 각 단어의 포함된 갯수를 통해서 vertor로 표현할 수 있다.
- 데이터가 많아지면 확률분포나 사전확률 등 그런 것이 의미가 없어질 정도로 강력해진다.
Ngram
- Ngram을 사용하면 Feature의 갯수가 많아짐(장점이자 단점)
Chunk
- Chunk단위(구)로 나눠서 사용하면 더 많아짐
Full Text Indexing
- 모든 문자를 다 씀(구두점까지 포함)
결론
- 없앨 것은 없애고 상관관계를 잘 분석하여 데이터를 사용해야 한다.
- 형태소 분석, 구두점 제거, 토큰화, zip’s law, BPE 알고리즘, Stopwords 사용
핵심 사진

'데이터 분석가 역량' 카테고리의 다른 글
| day 17 ] Document, Lexicon, Posting 구조 (0) | 2019.05.24 |
|---|---|
| day 16 ] PreProcessing => Lexicon까지 정리 및 실습 (0) | 2019.05.22 |
| day 15 ] 내 데이터로 출력해보기 (0) | 2019.05.21 |
| day 15 ] grammar (0) | 2019.05.21 |
| day 15 ] GitHub (0) | 2019.05.20 |