
1. Zipf's law
# zipf's law => 상위와 하위를 뺀 중간 값을 사용하는 알고리즘 => 불용어 처리
import os
import matplotlib.pyplot as plt
from math import log
from konlpy.tag import Okt # => twitter였는데 이름이 바뀜
ma = Okt() # 빠르게 형태소 분석을 해준다.
base = "./scraping/"
#for _ in [_ for _ in os.listdir(base)]: # 데이터 하나씩 불러오기
morphemes = list()
for _ in [_ for _ in os.listdir(base)][:1000]:
with open(base + _) as fp:
text = fp.read() # 파일을 읽어옴
for sentence in sent_tokenize(text):
morphemes.extend(ma.morphs(sentence))
obj = Text(morphemes)
x = range(len(obj.vocab().most_common())) # vocab => 센텐스를 각 어절로 나누어줌, most_common => 가장 높은 순으로 출력해줌
#x = [_[0] for _ in obj.vocab().most_common(500)]
y = [_[1] for _ in obj.vocab().most_common()] # 해당 어절의 수의 갯수를 배열형태로 저장
yy = [log(_) for _ in y] # y의 log(선형된 결과를 뽑아내기 위해서)
plt.plot(x, y, 'r-')
plt.show()
plt.plot(x, yy, 'b-')
plt.show()

2. Heap's law
# Heap's law => 상위와 하위를 뺀 중간 값을 사용하는 알고리즘 => 불용어 처리
import os
import matplotlib.pyplot as plt
from math import log
from konlpy.tag import Okt # => twitter였는데 이름이 바뀜
ma = Okt() # 빠르게 형태소 분석을 해준다.
k = 50
b = 0.5
# M = kT^b
base = "./scraping/"
text = ""
morphemes = list()
for _ in [_ for _ in os.listdir(base)][:50]: # for 모든 파일
tokens = list()
with open(base + _) as fp:
text += fp.read() # 파일 내용
for sentence in sent_tokenize(text): # 토큰화(어절로 나눔)
tokens.extend(ma.morphs(sentence)) # 형태소 분석 결과를 morphens를 누적하면서 쌓아감(점차 커지는 리스트: tokens)
morphemes.append(tokens) # 점차 커지는 token 집합을 쌓음
obj = Text(morphemes) #
x = [len(_) for _ in morphemes]
y = [k*_**b for _ in x]
yy = [len(set(_)) for _ in morphemes]
plt.plot(x, y, 'r-')
plt.plot(x, yy, 'b-')
plt.show()
1) 결과

2) 로그 결과
x = [log(len(_)) for _ in morphemes]
y = [log(k)+b*log(_) for _ in x]
yy = [log(len(set(_))) for _ in morphemes]
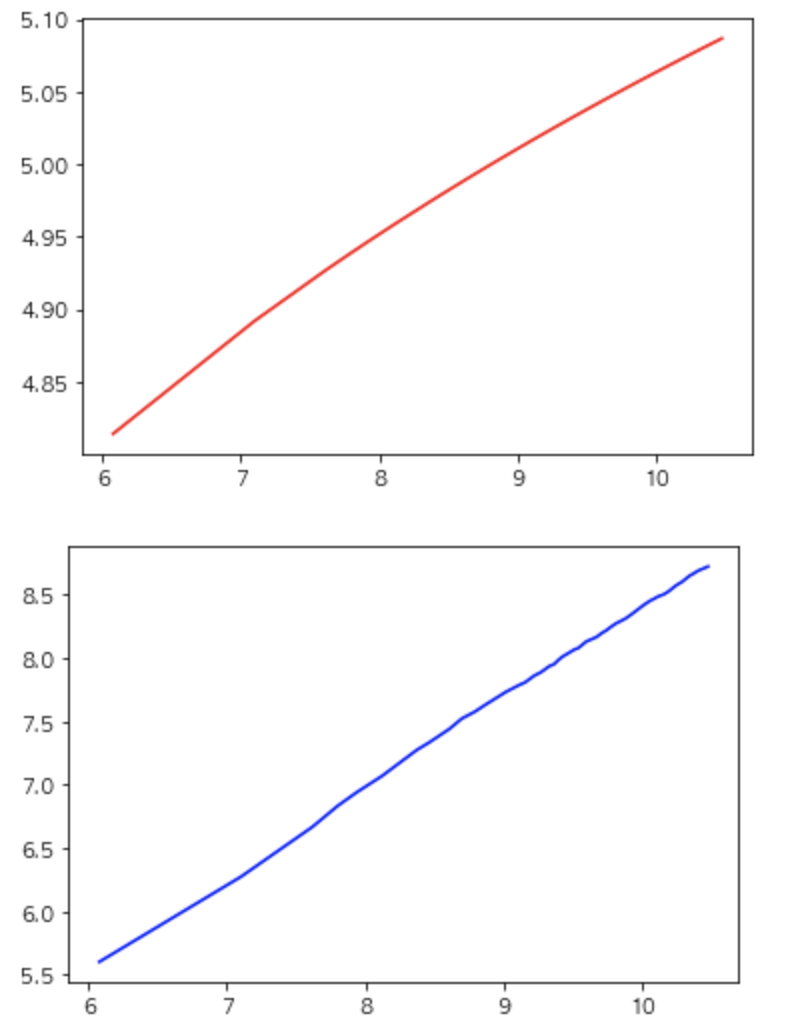
plt.plot(x, y, 'r-')
plt.show()
plt.plot(x, yy, 'b-')
plt.show()
'데이터 분석가 역량' 카테고리의 다른 글
| day 12] BPE (0) | 2019.05.15 |
|---|---|
| day 11 ] N-Gram (0) | 2019.05.15 |
| day 10 ] 형태소 분석 심화 (0) | 2019.05.14 |
| day 10 ] 형태소 분석 개론 (0) | 2019.05.14 |
| day 9 ] 데이터 학습 개론 (0) | 2019.05.13 |