
1. NLTK
- NLTK를 사용하는 이유는 띄어쓰기만으로 구분하여 처리하는 경우 제대로 형태소 분석이 되지 않기 때문에 이러한 형태소 분석을 제대로 해주는 패키지를 사용한다.
1) tokenize, splitlines
- tokenize: 문장을 나눔(문장을 마치는 문자를 인식하여)
- splitlines: 줄바꿈으로 나눔
2) word_tokenize, split
- word_tokenize: 어절을 나눔(어절을 마치는 문자를 인식하여)
- split: 띄어쓰기로 나눔
3) TweetTokenizer().tokenize
- 서양권에서 자주 사용되는 감정표시를 하나의 단어로 분류

4) word_tokenize의 preserve_line 옵션
- 구분자로 사용되는 .이 앞에 붙었는지 뒤에 붙었는지 알 수 있게하려면 True로 필요없다면 False를 둔다.

2. 단어의 빈도수
1) vocab
- collections에서 제공되기도 하지만 nltk의 Text에서 vocab을 통해 얻을 수 있다.

2) plot
- 그래프로 보기

3) 내가 가지고 있는 데이터로 해보기
- 모든 데이터를 하나의 문자열로 합쳐서 이것을 copus로 사용


4) 데이터 분석
- 특정 단어가 몇번 반복되었는지 확인

- 특정 단어가 어느 문단에서 나왔는 지
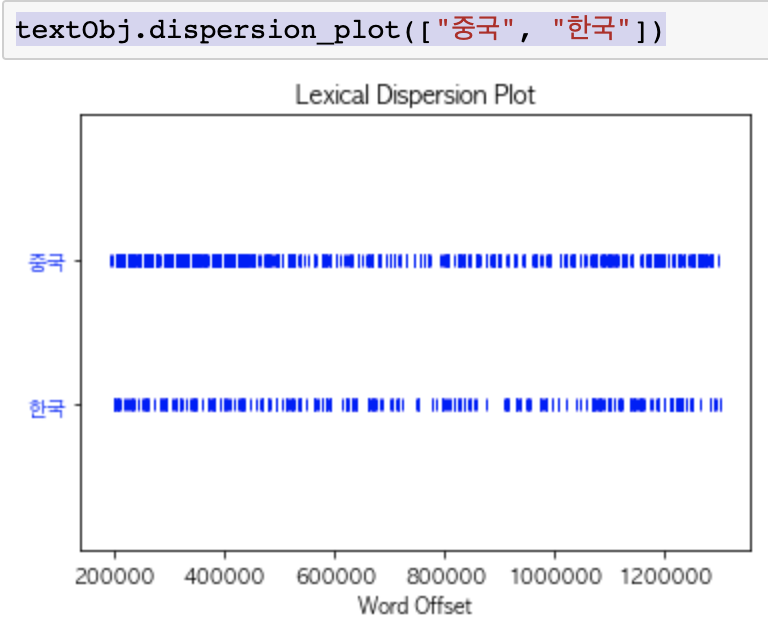
- 어디에서 매칭되었는지(잘모름 다시 알아보기)

- 어떤 글자들이 주제가 되는지

'데이터 분석가 역량' 카테고리의 다른 글
| day 11 ] N-Gram (0) | 2019.05.15 |
|---|---|
| day 11 ] 형태소 분석 (0) | 2019.05.15 |
| day 10 ] 형태소 분석 개론 (0) | 2019.05.14 |
| day 9 ] 데이터 학습 개론 (0) | 2019.05.13 |
| day 7 ] selenium (0) | 2019.05.09 |