
1. 설치
1) recognizer
https://nlp.stanford.edu/software/CRF-NER.html#Download
2) tagger
https://nlp.stanford.edu/software/tagger.html#Download

3) 환경 설정
- 경로를 설정 값으로 준다
- 오류가 발생한다면 경로가 잘못된 경우
from nltk.tag.stanford import StanfordPOSTagger
MODEL = "/Users/songsion/Downloads/stanford-postagger-full-2018-10-16/models/english-bidirectional-distsim.tagger"
PARSER="/Users/songsion/Downloads/stanford-postagger-full-2018-10-16/stanford-postagger-3.9.2.jar"
pos = StanfordPOSTagger(MODEL, PARSER)
4) 테스트
pos.tag(word_tokenize(sent_tokenize(corpus)[0]))

2. pos_tag
- 형태소의 각 부분을 분리해서 표현해줌
1) 각 형태소의 사용량
from nltk import Text
Text([_[1] for _ in posTags]).plot(10)
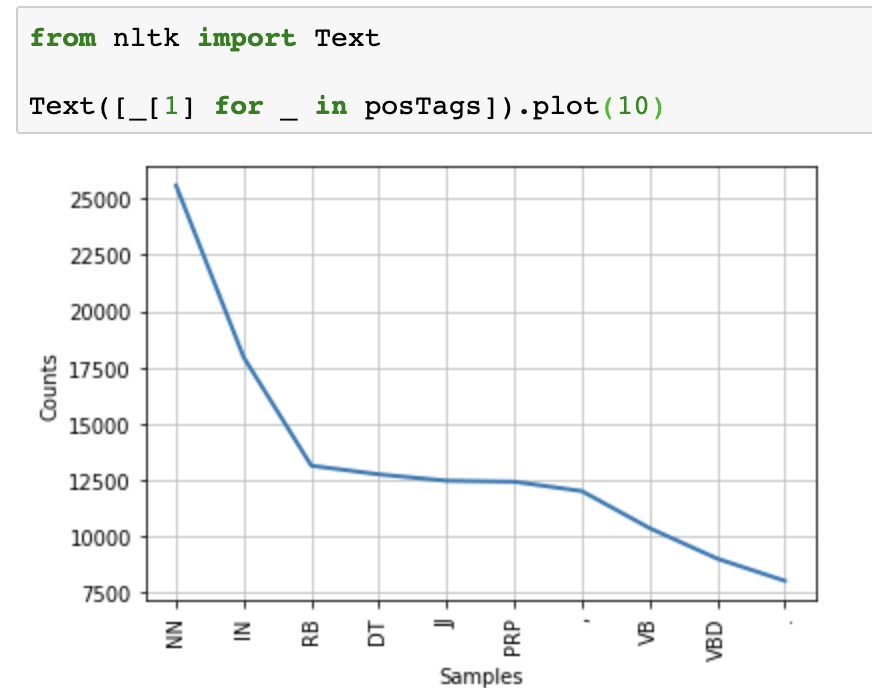
2) 형태소의 갯수를 보고 특정 형태소만 제외시키기
from nltk import pos_tag, word_tokenize
from nltk.help import upenn_tagset
from nltk.corpus import gutenberg
corpus = gutenberg.open("austen-emma.txt").read()
tokens = word_tokenize(corpus)
[_[0] for _ in pos_tag(tokens) if _[1] not in ["DT", "IN"]]
3. 한국어 데이터에 적용
- 국립국어원 (https://ithub.korean.go.kr/user/main.do#)
- 꼬마(Kkma) http://kkma.snu.ac.kr/
1) 형태소 분석기 - 한나눔
from konlpy.tag import Kkma # 형태소 분석기들(성능이 다 다름)
Kkma = Kkma()
sentence = "아버지가방에들어가신다."
print(Kkma.pos(sentence))
sentence = "아버지가 방에 들어가신다."
print(Kkma.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 인싸"
print(Kkma.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 창렬하다 혜자스럽게"
print(Kkma.pos(sentence))

2) 형태소 분석기 - Kkma
from konlpy.tag import Kkma # 형태소 분석기들(성능이 다 다름)
Kkma = Kkma()
sentence = "아버지가방에들어가신다."
print(Kkma.pos(sentence))
sentence = "아버지가 방에 들어가신다."
print(Kkma.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 인싸"
print(Kkma.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 창렬하다 혜자스럽게"
print(Kkma.pos(sentence))

3) 형태소 분석기 - komora
from konlpy.tag import Komoran # 형태소 분석기들(성능이 다 다름)
komoran = Komoran()
sentence = "아버지가방에들어가신다."
print(komoran.pos(sentence))
sentence = "아버지가 방에 들어가신다."
print(komoran.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 인싸"
print(komoran.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 창렬하다 혜자스럽게"
print(komoran.pos(sentence))

4) 형태소 분석기 - Okt
from konlpy.tag import Okt # 형태소 분석기들(성능이 다 다름)
okt = Okt()
sentence = "아버지가방에들어가신다."
print(okt.pos(sentence))
sentence = "아버지가 방에 들어가신다."
print(okt.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 인싸"
print(okt.pos(sentence))
sentence = "아이폰 갤럭시 안드로이드 창렬하다 혜자스럽게"
print(okt.pos(sentence))

5) 성능 결과
(문어체) Kkma = Komoran > Hannanum > Okt
(구어체) Komora > Okt = Hannanum > Kkma
(신조어,비속어) Komoran > Okt = Hannanum > Kkma
'데이터 분석가 역량' 카테고리의 다른 글
| day 15 ] grammar (0) | 2019.05.21 |
|---|---|
| day 15 ] GitHub (0) | 2019.05.20 |
| day 12 ] 불용어 (0) | 2019.05.16 |
| day 12] BPE (0) | 2019.05.15 |
| day 11 ] N-Gram (0) | 2019.05.15 |